クオンツトピックス
No.8
AIによるテキスト情報の解析(テキストデータの特徴を掴む)2
2018年12月20日号

投資工学開発室
吉野 貴晶
金融情報誌「日経ヴェリタス」アナリストランキングのクオンツ部門で16年連続で1位を獲得。ビックデータやAI(人工知能)を使った運用モデルの開発から、身の回りの意外なデータを使った経済や株価予測まで、幅広く計量手法を駆使した分析や予測を行う。

投資工学開発室
髙野 幸太
ニッセイアセット入社後、ファンドのリスク管理、マクロリサーチ及びアセットアロケーション業務に従事。17年4月より投資工学開発室において、主に計量的手法やAIを応用した新たな投資戦略の開発を担当する。
単語間の共起とは?
5. 共起分析
さて、クラスタリングされた文書について、その文書の特徴を人間が把握する方法を考えてみたいと思います。簡単な方法としては、各クラスター内で平均ベクトルとのコサイン類似度が高い文書を眺める方法や、各クラスター内で頻出する単語が何かを比較する方法、等が考えられます。計算コストが低く、差が出れば納得しやすい手法だと思います。一方、文書数が非常に多い場合や、単語単体に着目するだけでは特徴が分からない場合も考えられます。そこで、単語と単語の関係性に着目する手法として、今回は共起分析を試してみます。なお、共起分析自体は以前からある手法であり、AI(機械学習)の領域ではありませんが、AIの結果を人が確認する手法の例として今回は提示します。
5_1. 共起の定義
まず始めに、共起とは何か?を定義しないといけません。今回の分析における共起とは、「ある2つの単語のペアが、1つの文書(回答)の中に含まれていれば共起である」とします。また、共起関係の強さを表す指標には、今回はJaccard係数を利用します。整理したものが図8です。
図8. 共起関係とJaccard係数の定義
「販売」と「売上」の共起度を計算する例

Jaccard係数
= 単語Aも単語Bも含まれる文書の数
÷(単語Aが含まれるが単語Bが含まれない文書の数
+単語Bが含まれるが単語Aが含まれない文書の数
+単語Aも単語Bも含まれる文書の数)
= 40÷(60+60+40)
= 0.25
共起ネットワークの作成
6. 共起関係を図示する
先ほど計算した共起度について、人が見て考えられるように図示したいと思います。今回はネットワーク分析を利用します。
6_1. 共起ネットワークの図示
先ほど計算した共起関係を図示したものが図9です。丸い部分(ノード)は単語を表し、共起関係にある単語間が線(エッジ)で結ばれています。共起度が大きいほど、線が太くなっています。円状に表現したため、一部の単語は円の外周上に表示されていますが、関係性は確認できます。なお、この共起ネットワークを作成する過程では、余りに共起度が低いものや、余りに出現頻度が高く、その単語が意味を成しづらいものは除外しています。
図9. クラスター0における共起ネットワーク
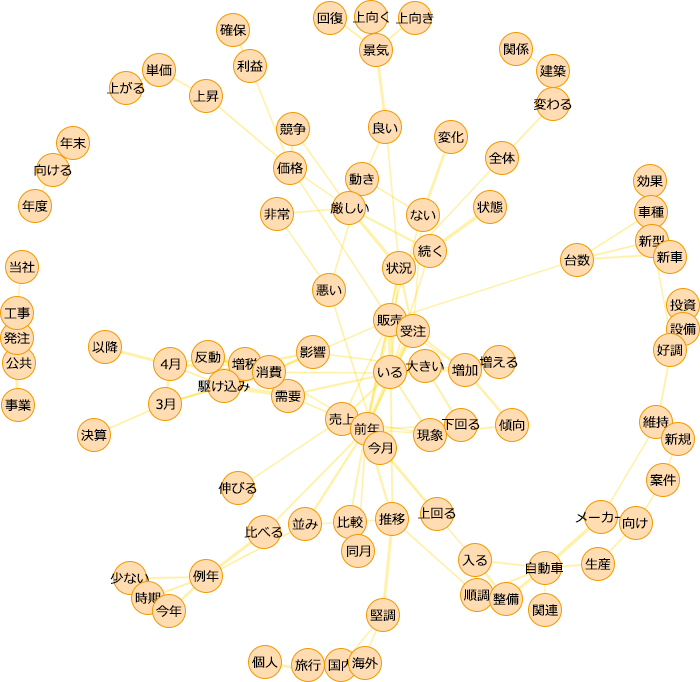
共起ネットワークから何が読み取れるか?
6_2.共起ネットワークを部分的に眺める
共起ネットワークの全体を俯瞰するのも重要ですが、一部に焦点を絞って眺めるのも有効です。以下の図10は筆者が切り取ったネットワークの一部です。このクラスターには、図10に記載したテーマの単語、文章が含まれていることが推測されます。また、単語群を繋ぐ単語にも注目することで、各単語群の関係性を発見する手助けになることも期待されます。このように、共起ネットワークを作成すると、大量の文書から特徴を見つけ出せる可能性があります。
図10. 共起ネットワークの部分的な関係性
消費税増税に関連する単語群
工事に関連する単語群
自動車メーカーなどに関する単語群
旅行に関連する単語群
自動車メーカーや設備投資に関する単語群
様々な手法を比較検討することが重要
7. 他の手法との兼ね合い
今回のレポートでは、大量のテキストデータに対してAIによる自動分類、並びに人が理解するために共起ネットワークの可視化を実施しました。この手法は大量のデータセットがある場合に、人手をかけずに知見を得る上で効果を発揮します。または、このクラスタリングをした後に、さらに後続として別のAI処理を噛ませる場合も有効だと思います。一方で、そもそもAIによって文章をベクトル化してグループ分けすることに対しては、どうしても解釈性の問題が付きまといます。結果の解釈が困難な場合が考えられるためです。
テキストデータを分類する方法は他にも考えられます。ある程度人手で付けたラベルデータが既にあるならば、それを教師データとして、ニューラルネットなどでラベル付け用モデルを構築することも考えられます。また、トピックモデルという手法もあります。これはAIが文書をトピック(単語など)でグループ分けする手法です。
上記のように、様々な手法がありますが、どの手法が適しているかはケースバイケースです。ユーザーのニーズにも依存しますし、複数の手法を組み合わせた方がベストな場合もあります。投資工学開発室が取り組んでいる投資手法の開発においても、同じ問題に直面します。技術が進化する一方、複数の手法を理解し、実装して比較できることが、現在は最も重要なのかもしれません。
8. 終わりに
次回レポートでも引き続きAIをテーマに取り扱う予定です。投資手法に活用するための挑戦をベースとし、テキストデータの解析手法を継続するか、画像処理系を予定しています。(都合により変更になることがあります)
Appendix
A-1. 参考文献
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, Jeffrey Dean
Distributed Representations of Words and Phrases and their Compositionality. - PySpark, NetworkXを利用した単語共起ネットワークの並列分散処理と可視化
クオンツトピックス
関連記事
- 2022年03月15日号
- 仮想レバレッジNASDAQを用いたFIREシミュレーション part1
- 2022年02月15日号
- “マジックフォーミュラ”を使った銘柄選別効果
- 2022年01月13日号
- 外国人投資家の売買動向の季節性
- 2021年12月22日号
- PBRとROEの関係から株価水準を考える
- 2021年12月15日号
- 非ユークリッド距離空間の見える化
「クオンツトピックス」ご利用にあたっての留意点
当資料は、市場環境に関する情報の提供を目的として、ニッセイアセットマネジメントが作成したものであり、特定の有価証券等の勧誘を目的とするものではありません。
【当資料に関する留意点】
- 当資料は、信頼できると考えられる情報に基づいて作成しておりますが、情報の正確性、完全性を保証するものではありません。
- 当資料のグラフ・数値等はあくまでも過去の実績であり、将来の投資収益を示唆あるいは保証するものではありません。また税金・手数料等を考慮しておりませんので、実質的な投資成果を示すものではありません。
- 当資料のいかなる内容も、将来の市場環境の変動等を保証するものではありません。
- 手数料や報酬等の種類ごとの金額及びその合計額については、具体的な商品を勧誘するものではないので、表示することができません。
- 投資する有価証券の価格の変動等により損失を生じるおそれがあります。